
I had a working AI skill for engineering tasks.
At first, it looked like a normal instruction: role, task, response format, and a few constraints. That was enough while the scenarios were short: look at a code fragment, suggest a plan, analyze an obvious error.
Then the skill started receiving more complex tasks.
For example: “review this PR before merge.”
There is a lot of hidden work inside that short request. You need to understand what is changing, which constraints exist, where the risk may be, what the conclusion is based on, which remarks actually block the change, and which ones are only suggestions.
Each new mistake added another rule to the instruction.
The AI suggested a fix too quickly — so I added a requirement to first define the boundary of the task.
It mixed important findings with taste-based edits — so I added a rule to separate blockers, questions, and suggestions.
It wrote confident conclusions without checking the evidence — so I added a section about evidence.
The answer became technically correct, but hard to read — so I added an editorial rule.
This is how an ordinary prompt gradually turns into a working protocol.
At some point, the problem is no longer only in the content. The problem is in the form itself: one text is trying to hold the work of an input analyst, developer, architect, risk reviewer, QA specialist, and final editor.
I call this structure a skill council: one AI skill for the user, but several clearly separated areas of responsibility inside it.
What I Mean by an AI Skill
By AI skill, I mean a stable instruction for a repeated work scenario.
It can be a skill for Codex, a custom assistant, a system prompt, a set of rules inside a repository, or any similar mechanism. The tool name is secondary. What matters is the working meaning: the user brings a task of the same type, and the AI handles it in an expected order.
Examples of such scenarios:
- reviewing a pull request;
- analyzing a bug;
- preparing a safe change plan;
- checking a release list;
- preparing a handoff after a long task — meaning transferring the task state to another person or another AI session;
- turning draft documentation into something usable.
As long as the scenario is simple, a short instruction works well enough.
But repeated engineering work quickly accumulates details. You need to understand the input, keep constraints in mind, see risks, verify the result, and return an answer that a human can act on.
A skill council appears at the point where it becomes useful to explicitly name different kinds of checks inside one skill.
Why a Large Prompt Starts Getting in the Way
A large prompt often grows from the right reaction to mistakes.
The model rushes to change code — so we add a rule: first understand the task.
It misses risk — so we add a separate block about data, access rights, and compatibility.
It writes a vague conclusion — so we add a requirement to state what the conclusion is based on.
It loses the right tone — so we add editorial requirements.
All of these rules are useful on their own. The difficulty begins when they sit in one common stream.
The model has to read the input, plan the action, check architectural consequences, look for risk, think about tests, and write the final response at the same time.
For a small task, this is acceptable.
For a task with several layers, the answer may look neat, while the actual review process remains hidden.
The user only sees the final text. They have to reconstruct on their own:
- which facts the AI considered reliable;
- where the AI saw risk;
- why a finding became blocking;
- what the conclusion is based on;
- what remained an assumption;
- whether the change can be accepted.
Such an answer may be pleasant to read and still weak as an engineering tool.

How the Skill Council Is Structured
From the outside, everything stays familiar: the user talks to one AI skill and receives one final answer.
Inside, the task passes through several roles.
| Role inside the skill | What it is responsible for | When it should stop the work |
|---|---|---|
| Input specialist | Understands what was provided: diff, task description, logs, constraints, missing data | When there is not enough context for a confident conclusion |
| Domain specialist | Looks at the meaning of the task in a specific domain | When the solution drifts away from the original problem |
| Action architect | Chooses the work order and the smallest safe change | When the plan touches an unclear area |
| Risk reviewer | Looks for data, access rights, compatibility, irreversible actions, and unexpected consequences | When there is a risk that cannot be closed by text alone |
| Quality reviewer | Looks at tests, reproduction, acceptance criteria, and evidence | When the conclusion cannot be verified |
| Result editor | Assembles the answer so that a human quickly understands the decision and next step | When a technically correct answer is hard to apply |
The role names can change depending on the task.
For code review, the emphasis is one thing. For a bugfix, another. For documentation, a third.
The main point is that each role does separate work: it finds its own type of problem, makes its own decision, or adds its own check.
For the user, the internal scheme only matters when it improves the result. A skill council keeps one convenient final answer and adds discipline behind it: the input is parsed, the risk is named, the verification is visible, and the result can be acted on.
Example: Pull Request Review
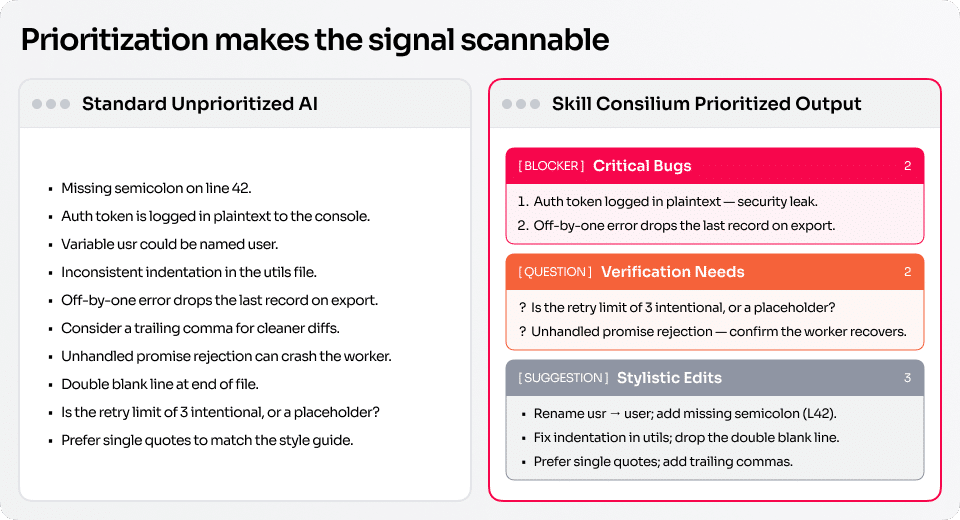
Take a short request: “review this PR.”
In a weak version, AI returns a list of remarks:
- The variable name could be improved.
- A test may be needed.
- Please check access rights handling.
- The code can be made more readable.Formally, there is a review.
Practically, it mixes cosmetic feedback, a possible test, an access-control risk, and a generic note about readability.
The PR author still has to understand what blocks the merge, which question needs clarification, and which points can be postponed.
In a skill council, the same request goes differently.
The input specialist checks whether there is a task description, a diff, tests, and important constraints.
The domain specialist checks whether the change solves the stated problem.
The action architect evaluates the scope: is this a local fix or a contract change?
The risk reviewer looks for places where a small change may affect users, data, access rights, or backward compatibility.
The quality reviewer checks what supports the conclusion: a test, reproduction, manual verification, or only reasoning.
The editor assembles the answer in a usable format:
Blockers:
- After an authorization error, the code returns cached data. This may show the user a stale state or data they no longer have access to.
Questions:
- Is there a test for the authorization failure scenario?
Suggestions:
- Separate fallback behavior for technical errors and access denial.
Conclusion:
- The PR is not ready to merge yet. Access denial must be handled explicitly and confirmed by a test.The value is in prioritization.
A serious finding gets the right weight. Uncertainty is named directly. The human understands what to do next.
Example: Bugfix
Another frequent request is: “Here is an error, fix it.”
This kind of request easily pushes AI to immediately look for a file and suggest a patch.
Sometimes that works.
In real development, a bugfix usually starts earlier: you need to understand the symptom, reproduction steps, environment, change boundaries, and verification method.
In the role-based structure, the input specialist separates facts from guesses:
- what exactly happened;
- where the log is;
- which steps reproduce the issue;
- which environment version is involved;
- what has already been checked.
The domain specialist looks for the likely area of the cause.
The action architect proposes the smallest path: where to look, what to change, and which options should stay outside the current fix.
The risk reviewer asks unpleasant questions:
- Does the change affect data?
- Are migrations involved?
- Are access rights affected?
- Does it change a public API?
- Does it touch background jobs?
- Can it create production risk?
The quality reviewer demands a confirmation scenario: a test, a command, reproduction before and after, manual verification, or an honest note that verification is still limited.
The final answer should be short but meaningful:
- what caused the bug;
- what was changed;
- how it was checked;
- what risk remains.
The most important part here is preserving the steps that an experienced developer usually keeps in their head.
What Changes in Practice
The first change: fewer blind spots
A general assistant often optimizes for the closest visible goal.
Asked for a review — it writes remarks.
Asked for a bugfix — it suggests a patch.
Asked for a plan — it builds a list of steps.
A role-based structure adds several mandatory questions before action:
- What is known?
- What is unclear?
- Where is the risk?
- How can the result be verified?
The second change: easier iteration
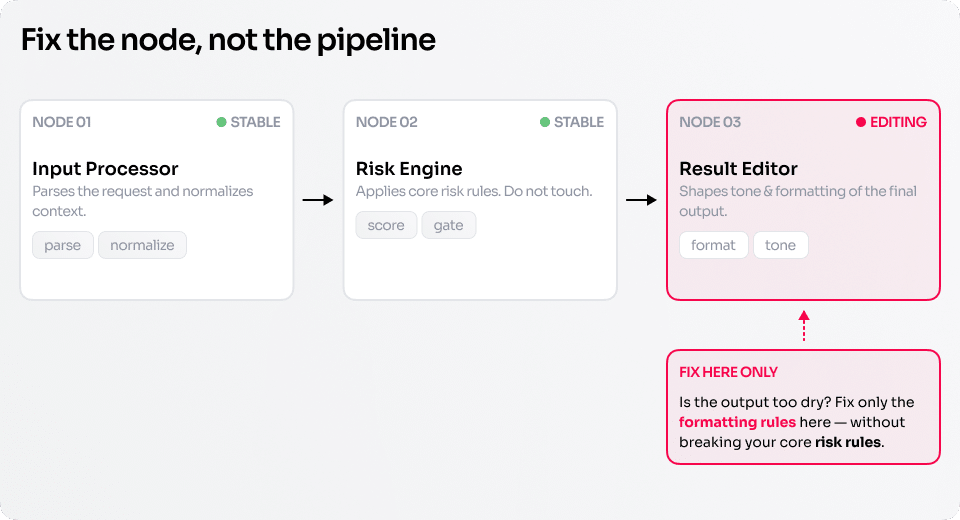
When everything lives in one prompt, it is difficult to understand what exactly broke.
Did the answers become too dry?
Did checks disappear?
Did risks become too soft?
Did the model start acting confidently with missing data?
Each new edit to the general prompt can accidentally damage neighboring behavior.
When responsibility zones are separated, the place of failure becomes visible faster.
If the skill adds unsupported facts, we strengthen input handling and work with sources.
If it misses risk, we improve the risk review role.
If conclusions are hard to apply, we adjust the final answer assembly.
If review turns into a long list of everything, we change the prioritization of findings.
The third change: gradual growth
At first, it may contain only an executor and a simple response format.
Then input checking appears.
Then a separate risk check.
Then quality and evidence.
Then a final editor.
New roles appear where a repeated task already requires a separate responsibility.
That kind of growth is clearer than trying to write the perfect prompt for every possible case from the beginning.
When This Is Worth Using
This approach pays off where the task has several layers of responsibility.
Good candidates
- a decision before merge;
- a bug with an unclear cause;
- a public API change;
- a release check;
- a task involving user data;
- a handoff after long work;
- reviewing material that will go public.
For small tasks, a role-based structure adds unnecessary weight.
Remembering a Git command, explaining a compiler error, fixing one sentence, or drafting a short code example is usually faster with a normal request.
Another risk: roles for the sake of roles
If every “specialist” says the same thing, the user gets noise.
If the final answer turns into a long discussion, the skill gets in the way.
Each role must either find a separate type of problem or make a separate working decision.
How to Try It Without a Separate Tool
The simplest experiment can be done directly in chat.
If your working prompt has already turned into a wall of rules, first try extracting one role: input checking or risk review.
Take a repeated scenario, such as PR review or bug analysis, and ask the AI to process the task by roles:
Analyze the task as a skill council inside one AI skill:
1. Input: what is known and what is missing.
2. Behavior: what changes for the system or user.
3. Risks: what may break or require caution.
4. Verification: what can confirm the conclusion.
5. Result: blockers, questions, suggestions, conclusion.After several runs, it becomes clear where AI most often fails.
If it invents missing facts, you need stricter input handling.
If it writes a smooth conclusion without verification, you need a quality role.
If it mixes blocking findings and nice-to-have suggestions, you need separate prioritization.
If the answer is hard to read, you need a result editor.
When the scenario repeats regularly, this structure can be turned into a stable AI skill.
What I Took From This Experience
The skill council helped me stop endlessly making one prompt heavier.
Instead of adding more and more rules to one general text, I started separating responsibility:
- who understands the input;
- who checks the domain logic;
- who chooses the action order;
- who looks for risk;
- who checks quality;
- who assembles the answer.
AI still makes mistakes.
Responsibility remains with the human.
But the skill starts behaving more calmly and more clearly: behind the confident text, visible working checks begin to appear.
In software engineering, this is especially important.
A good result here rarely comes down to one correct answer. The path matters: what was considered a fact, where the risk was, what confirmed the conclusion, and what decision the human should make.
Useful AI skills for engineering work, in my opinion, will move in exactly this direction: from hoping for one perfect prompt to clearly distributing responsibility inside the tool.
I am interested in how you solve a similar problem in your own work.






